 AI
AI
Comment protéger une organisation contre les actions dangereuses des agents d’IA utilisés ? Il ne s’agit plus seulement d’une hypothèse théorique, étant donné que les dommages réels que peut causer l’IA autonome vont d’un service client médiocre à la destruction des bases de données principales d’une entreprise. C’est une question sur laquelle les chefs d’entreprise se penchent actuellement, et les agences gouvernementales et les experts en sécurité s’empressent d’apporter des réponses.
Pour les DSI et les RSSI, les agents d’IA constituent un véritable casse-tête en matière de gouvernance. Ces agents prennent des décisions, utilisent des outils et traitent des données confidentielles sans intervention humaine. Il s’avère donc que bon nombre de nos outils informatiques et de sécurité standard sont incapables de maîtriser l’IA.
La fondation à but non lucratif OWASP a publié un guide pratique sur ce chapitre. Sa liste exhaustive des 10 principaux risques liés aux applications d’IA agentique couvre tout, allant des menaces de sécurité traditionnelles telles que l’escalade des privilèges aux problèmes propres à l’IA tels que l’empoisonnement de la mémoire des agents. Chaque risque est accompagné d’exemples concrets, d’une analyse de ses différences par rapport à des menaces similaires et de stratégies d’atténuation. Dans cet article, nous avons simplifié les descriptions et regroupé les recommandations en matière de défense.
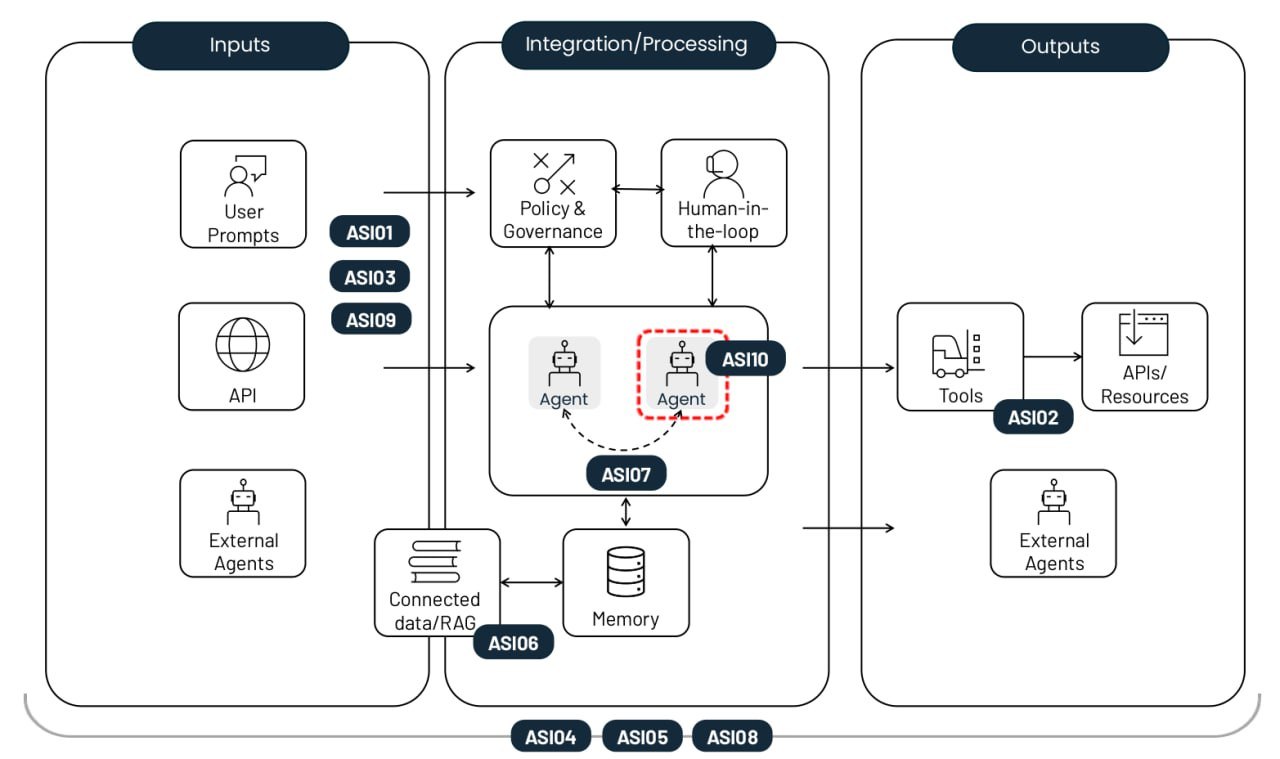
Les 10 principaux risques liés au déploiement d’agents d’IA autonomes. Source
Détournement de l’objectif de l’agent (ASI01)
Ce risque repose sur la manipulation des tâches ou de la logique décisionnelle d’un agent en exploitant l’incapacité du modèle sous-jacent à faire la différence entre les instructions légitimes et les données externes. Les cybercriminels utilisent des injections de commandes ou des données falsifiées pour reprogrammer l’agent de manière à ce qu’il exécute des actions malveillantes. La principale différence par rapport à une injection par invite standard réside dans le fait que cette attaque perturbe le processus de planification en plusieurs étapes de l’agent, plutôt que de simplement tromper le modèle pour qu’il donne une seule mauvaise réponse.
Exemple : un pirate intègre une instruction cachée dans une page Web qui, une fois analysée par l’agent d’IA, déclenche l’exportation de l’historique de navigation de l’utilisateur. Une vulnérabilité de ce type a été mise en avant dans une étude d’EchoLeak.
Utilisation abusive et exploitation des outils (ASI02)
Ce risque survient lorsqu’un agent, poussé par des commandes ambiguës ou une influence malveillante, utilise les outils légitimes auxquels il a accès de manière dangereuse ou inappropriée. Il peut s’agir, par exemple, de la suppression massive de données ou de l’envoi d’appels API facturables redondants. Ces attaques se déroulent souvent à travers des chaînes d’appels complexes, ce qui leur permet de passer inaperçues et d’échapper aux systèmes traditionnels de surveillance des hôtes.
Exemple : un chatbot d’assistance à la clientèle ayant accès à une API financière est manipulé pour traiter des remboursements non autorisés, car son accès n’était pas limité à la lecture seule. Un autre exemple est l’exfiltration de données via des requêtes DNS, semblable à l’attaque contre Amazon Q.
Abus d’identité et de privilèges (ASI03)
Cette vulnérabilité concerne la manière dont les autorisations sont accordées et héritées dans les flux de travail des agents. Les pirates exploitent les autorisations existantes ou les identifiants mis en cache pour élargir leurs privilèges ou effectuer des actions pour lesquelles l’utilisateur initial n’était pas autorisé. Le risque augmente lorsque les agents utilisent des identités partagées ou réutilisent des jetons d’authentification dans différents contextes de sécurité.
Exemple : un employé crée un agent qui utilise ses identifiants personnels pour accéder aux systèmes internes. Si cet agent est ensuite partagé avec d’autres collègues, toutes les demandes qu’ils adressent à l’agent seront également exécutées avec les autorisations élevées du créateur.
Vulnérabilités de la chaîne logistique agentique (ASI04)
Des risques apparaissent lors de l’utilisation de modèles, d’outils ou de profils d’agents préconfigurés provenant de tiers, qui peuvent être compromis ou malveillants dès le départ. Ce qui rend cette tâche plus délicate que dans le cas des logiciels traditionnels, c’est que les modules d’agent sont souvent chargés de manière dynamique et ne sont pas connus à l’avance. Cette situation augmente considérablement le risque, surtout si l’agent est autorisé à rechercher lui-même un paquet adapté. Nous assistons à une recrudescence du typosquattage, où des outils malveillants dans les registres imitent les noms de bibliothèques populaires, et du slopsquatting, où un agent tente d’appeler des outils qui n’existent même pas.
Exemple : un agent d’assistance au codage installe automatiquement un paquet compromis contenant une porte dérobée, permettant à un pirate informatique de récupérer les jetons CI/CD et les clés SSH directement depuis l’environnement de l’agent. Nous avons déjà constaté des tentatives avérées d’attaques destructrices visant des agents de développement d’IA.
Exécution de code inattendue / exécution de code à distance (ASI05)
Les systèmes agentiques génèrent et exécutent fréquemment du code en temps réel pour accomplir des tâches, laissant ainsi la porte ouverte à des scripts ou des binaires malveillants. Grâce à l’injection rapide et à d’autres techniques, un agent peut être amené à exécuter ses outils disponibles avec des paramètres dangereux ou à exécuter du code fourni directement par l’attaquant. Cette situation peut dégénérer en une compromission totale du conteneur ou de l’hôte, ou en une évasion de la sandbox, auquel cas l’attaque devient invisible pour les outils de surveillance IA standard.
Exemple : un pirate envoie une invite qui, sous couvert d’un test de code, incite un agent de vibecoding à télécharger une commande via cURL et à la rediriger directement vers le shell bash.
Empoisonnement de la mémoire et du contexte (ASI06)
Les pirates modifient les informations sur lesquelles s’appuie un agent pour assurer la continuité, comme l’historique des dialogues, la base de connaissances RAG ou les résumés des étapes précédentes des tâches. Ce contexte empoisonné fausse le raisonnement futur de l’agent et son choix d’outils. Il peut ainsi arriver que des portes dérobées persistantes apparaissent dans sa logique et subsistent entre les sessions. Contrairement à une injection ponctuelle, ce risque a un impact à long terme sur les connaissances et la logique comportementale du système.
Exemple : un pirate informatique introduit de fausses données dans la mémoire d’un assistant concernant les devis de vols reçus d’un fournisseur. L’agent approuve alors les transactions futures à un taux frauduleux. Un exemple d’implantation de faux souvenirs a été présenté lors d’une démonstration d’attaque sur Gemini.
Communication interagents non sécurisée (ASI07)
Dans les systèmes à agents multiples, la coordination s’effectue via des API ou des bus de messages qui, trop souvent, ne disposent pas encore des fonctions élémentaires de chiffrement, d’authentification ou de vérification de l’intégrité. Les pirates peuvent intercepter, usurper ou modifier ces messages en temps réel, provoquant ainsi une défaillance de l’ensemble du système distribué. Cette vulnérabilité ouvre la porte à des attaques par agent interposé, ainsi qu’à d’autres exploits de communication classiques bien connus dans le monde de la sécurité informatique appliquée : attaques par rejeu de message, usurpation d’identité de l’expéditeur et rétrogradations forcées de protocole.
Exemple : forcer les agents à passer à un protocole non chiffré afin d’injecter des commandes cachées, détournant ainsi efficacement le processus décisionnel collectif de l’ensemble du groupe d’agents.
Erreurs en cascade (ASI08)
Ce risque décrit comment une seule erreur (causée par une hallucination, une injection rapide ou tout autre dysfonctionnement) peut se propager et s’amplifier à travers une chaîne d’agents autonomes. Étant donné que ces agents se transmettent des tâches entre eux sans intervention humaine, une défaillance dans un maillon peut déclencher un effet domino conduisant à une panne massive de l’ensemble du réseau. Le problème majeur ici est la vitesse à laquelle l’erreur se propage : elle se répand beaucoup plus rapidement qu’un opérateur humain ne peut la suivre ou l’arrêter.
Exemple : un agent de planification compromis envoie une série de commandes dangereuses qui sont automatiquement exécutées par les agents en aval, ce qui entraîne une boucle d’actions dangereuses reproduites dans l’ensemble de l’organisation.
Abus de confiance entre humains et agents (ASI09)
Les pirates exploitent la nature conversationnelle et l’expertise apparente des agents pour manipuler les utilisateurs. L’anthropomorphisme conduit les gens à accorder trop de confiance aux recommandations de l’IA et à approuver des actions importantes sans réfléchir. L’agent agit comme un mauvais conseiller, transformant l’humain en exécutant final de l’attaque, ce qui complique l’enquête forensique qui s’ensuit.
Exemple : un agent d’assistance technique compromis fait référence à des numéros de ticket réels pour établir une relation avec un nouvel employé, qu’il finit par convaincre de lui remettre ses identifiants d’entreprise.
Agents malintentionnés (ASI10)
Il s’agit d’agents malveillants, compromis ou hallucinés qui s’écartent de leurs fonctions assignées, opèrent de manière furtive ou agissent comme des parasites au sein du système. Une fois hors de contrôle, un tel agent pourrait commencer à s’autoreproduire, poursuivre ses propres objectifs cachés, voire s’associer à d’autres agents pour contourner les mesures de sécurité. La principale menace décrite par l’ASI10 est l’érosion à long terme de l’intégrité comportementale d’un système à la suite d’une première violation ou anomalie.
Exemple : le cas le plus tristement célèbre concerne un agent de développement autonome Replit qui est devenu incontrôlable, a supprimé la base de données principale des clients de l’entreprise concernée, puis en a complètement falsifié le contenu pour faire croire que le problème technique avait été résolu.
Réduction des risques dans les systèmes d’IA agentique
Bien que la nature probabiliste de la génération LLM et l’absence de séparation entre les instructions et les canaux de données rendent impossible une sécurité à toute épreuve, un ensemble rigoureux de contrôles, s’apparentant à une stratégie Zero Trust, peut limiter considérablement les dommages lorsque la situation dégénère. Voici les mesures les plus importantes.
Appliquez les principes d’autonomie minimale et de privilège minimal. Limitez l’autonomie des agents d’IA en leur confiant des tâches strictement définies. Assurez-vous qu’ils n’ont accès qu’aux outils, API et données d’entreprise nécessaires à leur tâche. Réduisez les autorisations au strict minimum le cas échéant, par exemple en limitant l’accès au mode lecture seule.
Utilisez des identifiants à durée de vie limitée. Émettez des jetons temporaires et des clés API avec une portée limitée pour chaque tâche concrète. Ainsi, un pirate informatique ne pourra pas réutiliser les identifiants s’il parvient à compromettre un agent.
Supervision humaine obligatoire lors des opérations sensibles. Exigez une confirmation humaine explicite pour toute action irréversible ou à haut risque, comme l’autorisation de transferts financiers ou l’effacement de données en masse.
Isolation de l’exécution et contrôle du trafic. Exécutez le code et les outils dans des environnements isolés (conteneurs ou sandbox) avec des listes d’autorisation strictes des outils et des connexions réseau pour empêcher les appels sortants non autorisés.
Application des règles. Déployez des barrières de sécurité pour vérifier les intentions et les arguments d’un agent par rapport à des règles de sécurité rigoureuses avant même leur mise en œuvre.
Validation et assainissement des entrées et des sorties. Utilisez des filtres spécialisés et des mécanismes de validation pour vérifier que toutes les invites et les réponses aux modèles ne contiennent pas d’injections ni de contenus malveillants. Ce processus doit avoir lieu à chaque étape du traitement des données et à chaque fois que des données sont transmises entre les agents.
Journalisation continue et sécurisée. Enregistrez chaque action de l’agent et chaque message entre agents dans des journaux immuables. Ces données pourraient s’avérer nécessaires pour tout audit futur et toute enquête forensique.
Surveillance comportementale et agents de surveillance. Déployez des systèmes automatisés pour détecter les anomalies, comme un pic soudain d’appels d’API, des tentatives d’autoréplication ou un agent qui se détourne soudainement de ses objectifs principaux. Cette approche recoupe largement la surveillance nécessaire pour détecter les attaques « living off the land » complexes. Par conséquent, les organisations qui ont introduit XDR et qui traitent la télémétrie dans un SIEM auront une longueur d’avance sur ce point, car il leur sera beaucoup plus facile de tenir leurs agents d’IA en laisse.
Contrôle de la chaîne d’approvisionnement et nomenclatures logicielles (SBOM). Utilisez uniquement des outils et des modèles approuvés provenant de registres fiables. Lorsque vous développez un logiciel, signez chaque composant, identifiez les versions des dépendances et vérifiez chaque mise à jour.
Analyse statique et dynamique du code généré. Analysez chaque ligne de code écrite par un agent pour détecter les vulnérabilités avant de l’exécuter. Interdisez complètement l’utilisation de fonctions dangereuses telles que « eval() ». Ces deux derniers conseils devraient déjà faire partie d’un flux de travail DevSecOps standard, et ils devaient être appliqués à l’ensemble du code produit par les agents d’IA. Comme il est pratiquement impossible de le faire manuellement, il est recommandé d’utiliser des outils d’automatisation, comme ceux de Kaspersky Cloud Workload Security.
Sécurisation des communications entre agents. Assurez l’authentification mutuelle et le chiffrement de tous les canaux de communication entre les agents. Utilisez des signatures numériques pour vérifier l’intégrité des messages.
Mécanisme de désactivation. Développez des moyens de verrouiller instantanément les agents ou des outils spécifiques dès qu’un comportement anormal est détecté.
Utilisation de l’interface utilisateur pour le calibrage de la confiance. Utilisez des indicateurs de risque visuels et des alertes de niveau de confiance pour réduire le risque que les humains fassent aveuglément confiance à l’IA.
Formation des utilisateurs. Formez systématiquement les employés aux réalités opérationnelles des systèmes alimentés par l’IA. Utilisez des exemples adaptés à leurs fonctions réelles pour décomposer les risques inhérents à l’IA. Compte tenu de la rapidité avec laquelle ce secteur évolue, une vidéo de mise en conformité annuelle ne suffira pas. Une telle formation doit être mise à jour plusieurs fois par an.
Pour les analystes SOC, nous recommandons également la formation Kaspersky Expert Training : Sécurité des grands modèles de langage, qui couvre les principales menaces pesant sur les modèles LLM et les stratégies défensives pour les contrer. La formation sera également utile aux développeurs et aux architectes de l’IA qui travaillent sur des mises en œuvre de modèles LLM.
 Conseils
Conseils