L'intelligence artificielle et le machine learning dans la cybersécurité
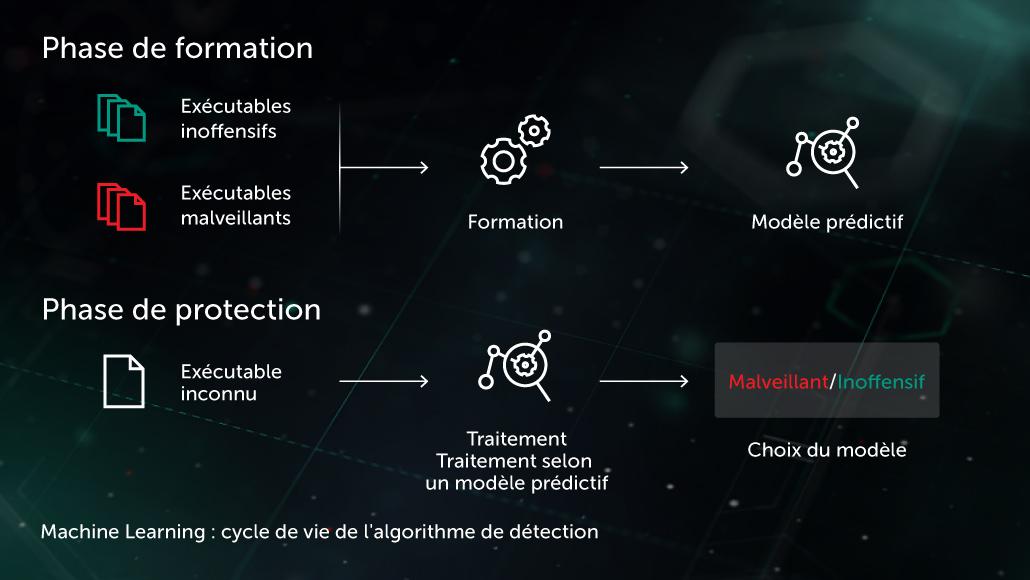
Arthur Samuel, précurseur de l'intelligence artificielle, décrivait l'IA comme un ensemble de méthodes et de technologies qui « donnent aux ordinateurs la faculté d'apprendre sans être explicitement programmés ». Dans un cas particulier d'apprentissage supervisé pour la lutte contre les programmes malveillants, la tâche pourrait être formulée comme suit : en partant d'un ensemble de fonctionnalités d'objets \( X \) et d'étiquettes d'objets correspondantes \( Y \), créer un modèle qui produira les étiquettes correctes \( Y' \) pour les objets de test \( X' \) qui n'ont pas encore été vus. \( X \) pourrait être une fonctionnalité représentant le contenu ou le comportement du fichier (statistiques du fichier, liste des fonctions API utilisées, etc.), et les étiquettes \( Y \) pourraient être simplement indiquer « malveillant » ou « bénin » (dans des cas plus complexes, nous pourrions envisager une classification plus détaillée, comme Virus, Trojan-Downloader, Adware, etc.). En cas d'apprentissage non supervisé, on s'attache davantage à révéler les structures cachées des données, p. ex., trouver des groupes d'objets similaires ou des caractéristiques étroitement corrélées.
La protection multi-niveaux de nouvelle génération de Kaspersky utilise largement les approches de l'IA telles que le ML à toutes les étapes du processus de détection : méthodes de mise en cluster évolutives utilisées pour le prétraitement des flux de fichiers entrants, modèles de réseaux neuronaux approfondis, robustes et compacts pour la détection comportementale, utilisés directement sur les machines des utilisateurs. Ces technologies sont conçues pour répondre à plusieurs exigences importantes pour les utilisations réelles en matière de cybersécurité, notamment un taux de faux positifs extrêmement faible, la possibilité d'interpréter les modèles et la robustesse face aux adversaires.
Penchons-nous sur les principales technologies de ML qui équipent les solutions de protection des terminaux Kaspersky :
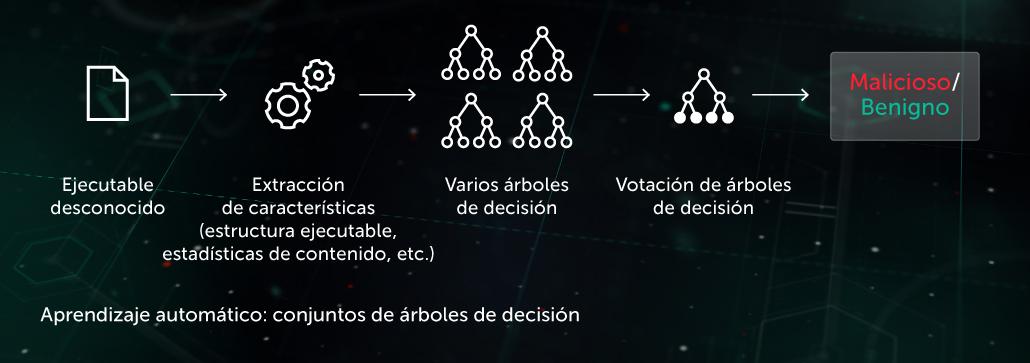
Arbre décisionnel
Dans cette approche, le modèle prédictif prend la forme d'un ensemble d'arbres décisionnels (p. ex, forêt d'arbres décisionnels ou arbres avec stimulation de gradient). Chaque nœud non terminal contient une question concernant les caractéristiques d'un fichier, alors que les nœuds terminaux contiennent la décision finale de l'arbre concernant l'objet. En phase de test, le modèle traverse l'arbre en répondant à des questions dans les nœuds avec les caractéristiques correspondantes de l'objet examiné. En phase finale, les décisions de plusieurs arbres font l'objet d'une moyenne à l'aide d'un algorithme spécifique pour rendre une décision finale de l'arbre concernant l'objet.
Le modèle bénéficie d'une protection proactive au stade de pré-exécution côté terminal. L'une de nos applications de cette technologie est Cloud ML for Android utilisée pour la détection des menaces mobiles.
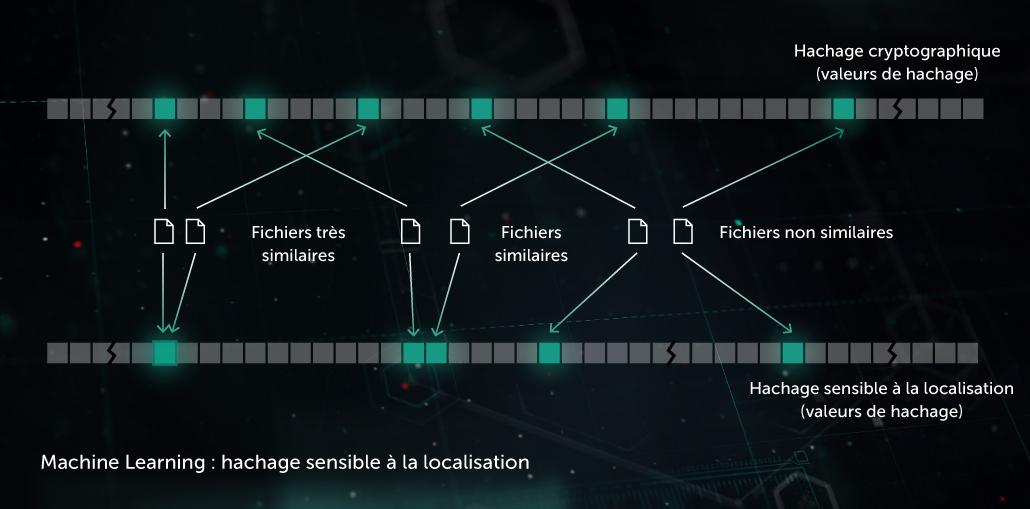
Hachage de similarité (hachage sensible à la localité)
Par le passé, les hachages utilisés pour créer les « empreintes » des programmes malveillants étaient sensibles à chaque petite modification de fichier. Les auteurs de programmes malveillants exploitaient cette faiblesse en usant de techniques dites d'« obfuscation », telles que le polymorphisme des programmes malveillants côté serveur : les petites modifications dans les programmes malveillants échappaient aux radars. Le hachage de similarité (ou hachage sensible à la localité) est une méthode d'IA qui permet de détecter des fichiers malveillants similaires. Pour ce faire, le fichier extrait des caractéristiques de fichiers et s'appuie sur l'apprentissage par projection orthogonale pour choisir les caractéristiques principales. Une compression basée sur le ML est ensuite appliquée de manière que des vecteurs de valeur de caractéristiques similaires se transforment en schémas semblables ou identiques. Cette méthode offre une bonne généralisation et réduit sensiblement la taille de la base de données de détection, puisqu'une donnée peut désormais détecter toute la famille de programmes malveillants polymorphes.
Le modèle bénéficie d'une protection proactive au stade de pré-exécution côté terminal. Elle est appliquée dans notre Système de détection avec hachage de similarité.
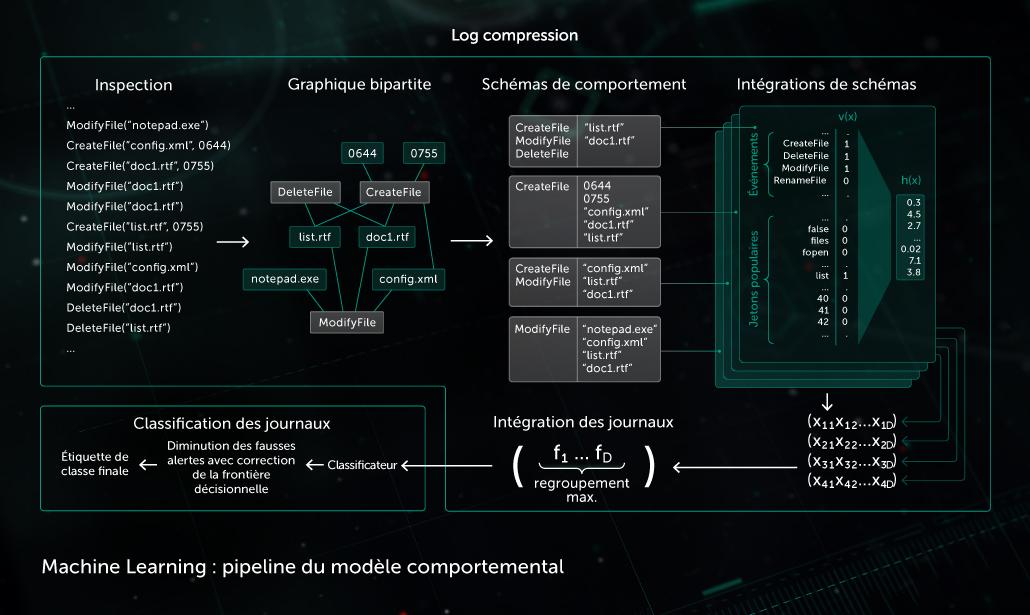
Modèle comportemental
Un composant de surveillance fournit un journal de comportements : la séquence d'événements système survenus pendant l'exécution du processus accompagnée des arguments correspondants. Afin de détecter l'activité malveillante dans les données de journal observées, notre modèle compresse la séquence d'événements obtenue dans un ensemble de vecteurs binaires et entraîne le réseau neuronal profond à faire la différence entre les journaux propres et les journaux malveillants.
La classification des objets effectuée par le modèle comportemental est utilisée par les modules de détection statique et dynamique dans les produits Kaspersky côté terminal.
L'IA joue également un rôle tout aussi important dans la mise en place d'une infrastructure adéquate de traitement des programmes malveillants en laboratoire. Kaspersky l'utilise dans le cadre de l'infrastructure à cet effet :
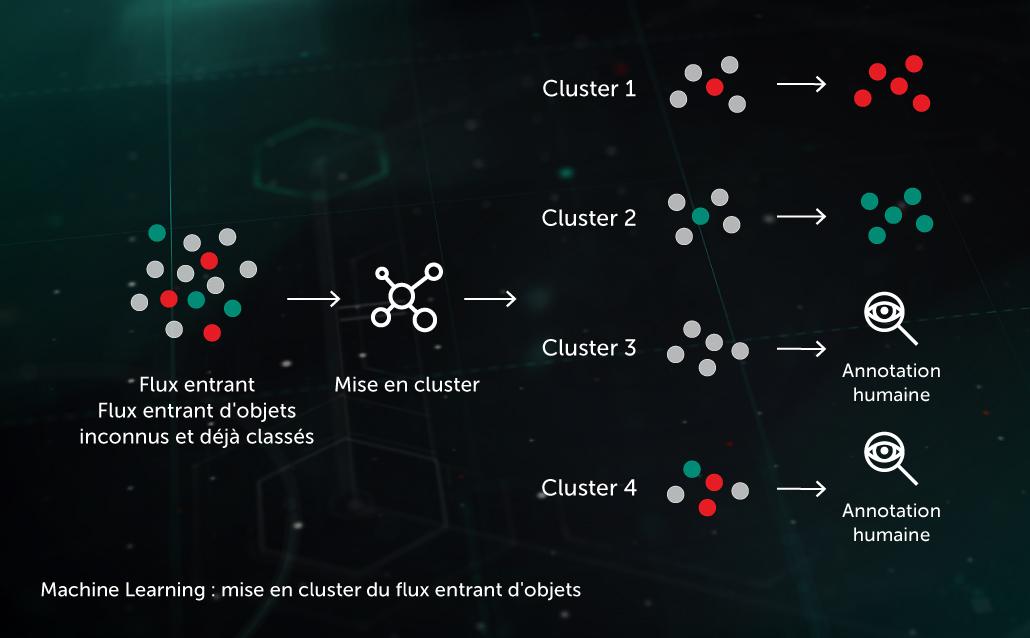
Mise en cluster de flux entrants
Les algorithmes de mise en cluster basés sur le ML nous permettent de répartir efficacement les volumes importants de fichiers inconnus arrivant sur notre infrastructure dans un nombre raisonnable de clusters, dont certains peuvent être traités automatiquement selon la présence d'un objet déjà annoté à l'intérieur.
Modèles de classification à grande échelle
Parmi les modèles de classification les plus performants, certains (tels qu'une immense forêt d'arbres décisionnels) nécessitent énormément de ressources (temps processeur, mémoire) ainsi que d'onéreux extracteurs de caractéristiques (p. ex., un traitement via une sandbox peut être requis pour obtenir des journaux de comportements détaillés). Par conséquent, il est plus efficace de conserver et d'exécuter le modèle en interne, avant de diffuser les connaissances acquises par ces modèles en entraînant un modèle de classification léger sur les décisions en matière de sortie du grand modèle.
Sécurité dans l'utilisation des aspects ML de l'IA
Une fois qu'ils ont franchi les murs internes pour être introduits dans le monde extérieur, les algorithmes de ML risquent d'être vulnérables à différentes formes d'attaques conçues pour forcer les systèmes d'IA à commettre délibérément des erreurs. Un cybercriminel peut infecter un ensemble de données d'entraînement ou faire l'ingénierie inverse du code du modèle. En outre, les pirates informatiques peuvent appliquer des techniques par force brute aux modèles de ML à l'aide de systèmes d'« IA antagoniste » spécialement développés, qui peuvent générer automatiquement de nombreux échantillons d'attaque et les lancer contre la solution de protection ou le modèle de ML extrait, jusqu'à ce qu'un point faible du modèle soit découvert. L'impact de telles attaques sur les systèmes de protection contre les programmes malveillants qui utilisent l'IA peut être dévastateur : un cheval de Troie qui n'est pas bien identifié est synonyme de millions d'appareils infectés et de pertes financières qui se comptent en millions d'euros.
Pour cette raison, il y a quelques considérations clés à appliquer lors de l'utilisation de l'IA dans les systèmes de sécurité :
- L'éditeur de solutions de sécurité doit comprendre et aborder avec sérieux les exigences indispensables au bon fonctionnement des composants de l'IA dans le monde réel, qui s'avère parfois hostile. Des exigences qui incluent la robustesse face aux adversaires potentiels. Les audits de sécurité propres au ML/IA et le « red-teaming » devraient être des modules clés dans le développement de systèmes de sécurité utilisant des aspects de l'IA.
- Lorsque vous évaluez la sécurité d'une solution qui fait appel à des composants de l'IA, demandez-vous dans quelle mesure la solution dépend de données et d'architectures tierces, car de nombreuses attaques reposent sur des données tierces (il s'agit de flux de Threat Intelligence, d'ensembles de données publiques, de modèles d'IA pré-entraînés et externalisés).
- Les méthodes de ML/IA ne doivent pas être considérées comme une solution miracle. Elles doivent s'inscrire dans une approche de sécurité multi-niveaux, où les technologies de protection complémentaires et l'expertise humaine œuvrent de concert, en se surveillant mutuellement.
Il est important de reconnaître que si Kaspersky a acquis une vaste expérience dans l'utilisation efficace des aspects de l'IA comme le ML et son sous-ensemble d'apprentissage profond dans ses solutions de cybersécurité, ces technologies ne sont pas de la véritable IA, ou de l'intelligence artificielle générale (AGI). Il faudra encore attendre longtemps avant que les machines puissent fonctionner de manière indépendante et effectuer la plupart des tâches de manière entièrement autonome. D'ici là, presque tous les aspects de l'IA dans la cybersécurité nécessiteront les conseils et l'expertise de professionnels humains qui développeront et affineront les systèmes, en faisant progresser leurs capacités au fil du temps.
Pour une présentation détaillée des attaques courantes contre les algorithmes de ML/IA ainsi que des moyens de protection contre ces menaces, consultez notre livre blanc « AI under Attack: How to Secure Artificial Intelligence in Security System » (L'IA attaquée ou comment sécuriser l'intelligence artificielle dans les systèmes de sécurité).
Produits associés





 Whitepaper
Whitepaper
WhitepaperMachine Learning for Malware Detection
Whitepaper
WhitepaperMachine learning and Human Expertise
Whitepaper
WhitepaperAI under Attack: How to Secure Machine Learning in Security System